I recently thought about an idea that could assist optometrists and ophthalmologists in diagnosing retinal pathologies using an image classifier. If somebody could provide a variety of retinal images taken through a variety of imaging machines and given a correct prognosis, an application could be built that takes any retinal image and be provided with a probability of a certain condition.
To explore this idea, I first did a search to see if any such applications/services exist. I quickly reviewed a few pages on google and was able to find something similar to my idea called EyeArt. This application does what I mentioned above but the model only looks at diabetic retinopathy. So it’s fair to assume that the model was fed a series of images with labels that classify the degree of the ailment. This is fine but is only specific to that disease. What if there was something that worked for a variety of different things?
I then started searching Kaggle for datasets that contained retinal images because this seems to be a very apparent application for machine learning. To my surprise, I found a variety of data sets with retinal images. Most of the datasets were for specific images but I found a single dataset that contained images and classification of a variety of diseases. Okay, so we have a start of an application. This dataset was produced for a specified paper but was not created to produce a consumable service for people to use.
To produce such an application, one would have to contact a large number of optometrists and ophthalmologists and request both anonymized images, and exact locations of specific diseases. You could then produce a service that can be used to both diagnose and identify where the diseases are. Below is an example of what they could see (this is an image of a normal retina that I built an example on top of):
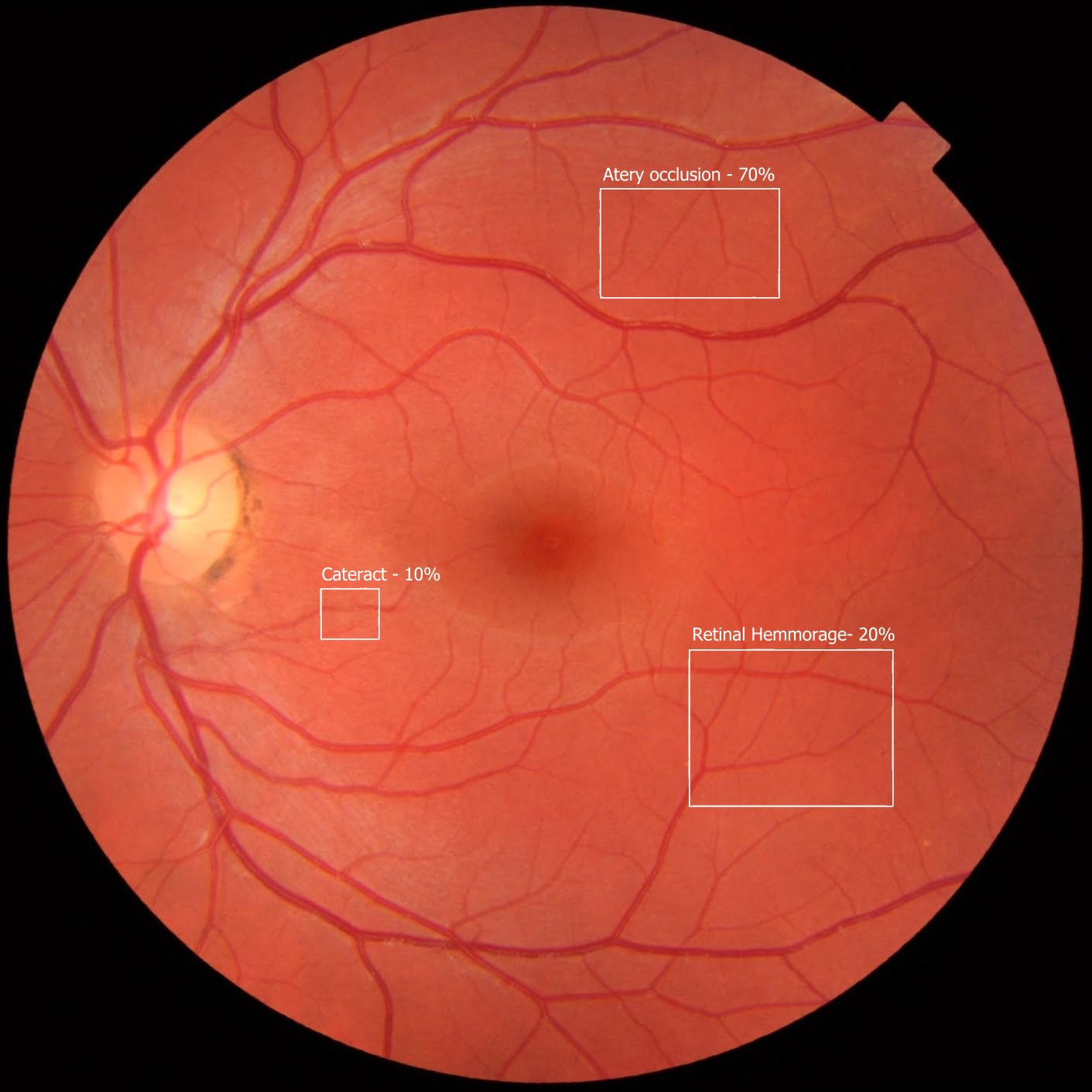
The application would require some initial training with the bounding box data and over time users could provide feedback on its quality which could be applied to the dataset and the model retrained to improve its quality.
A good starting point is to initially train the model using a tool that lets you classify visual data called Zendo. This application lets you build this exact type of model and then deploy the model as a service which you can then deploy and consume using a desktop application, web application, or mobile application.
If anybody is interested in working on such a service with me, let me know by leaving a comment below.
Leave a Reply