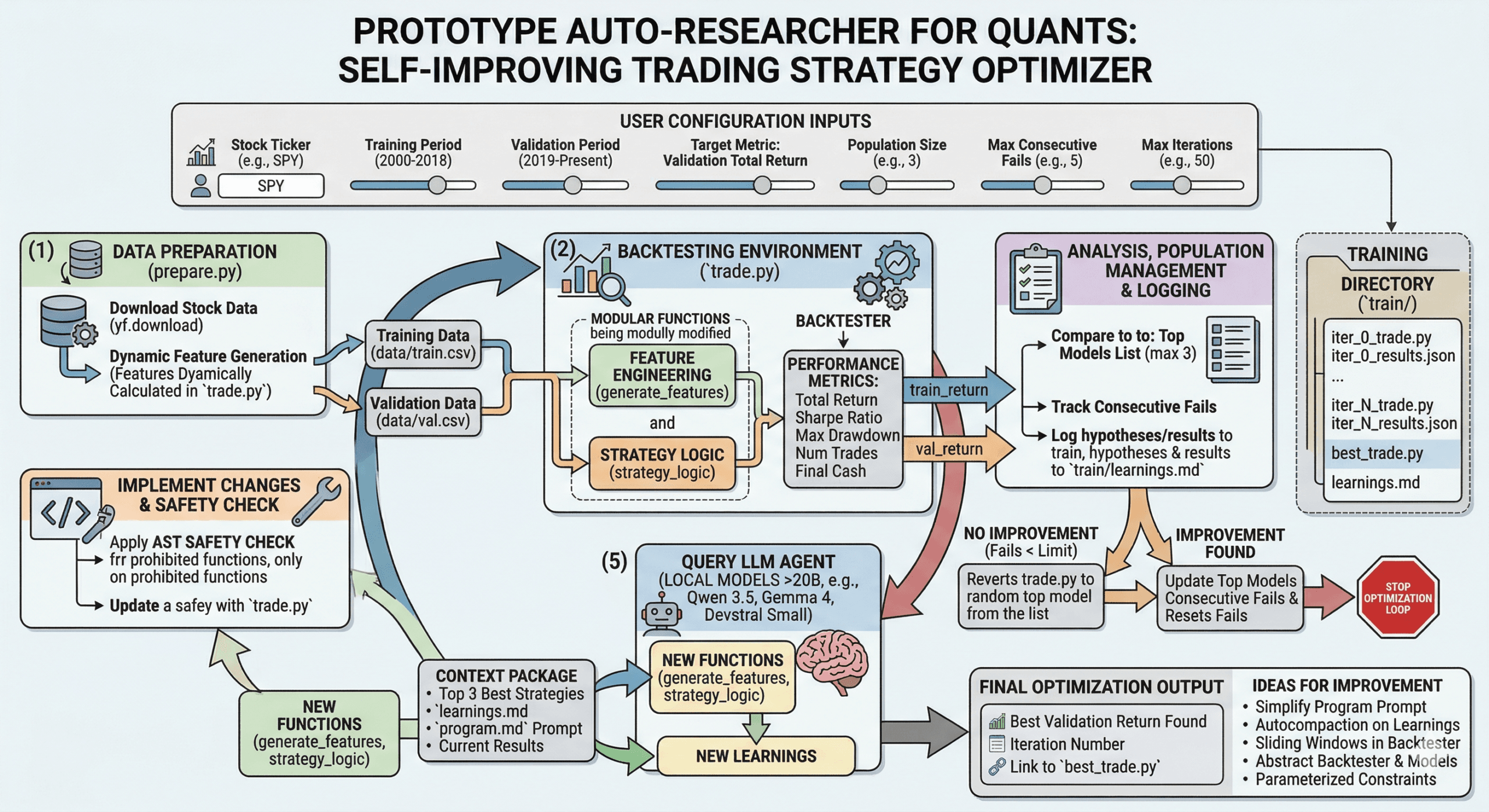
This last week, I was thinking about how Andrei Karpathy put together his Auto Researcher that autonomously improved how his nanochat model was trained end to end. I wondered if this could be applied to different applications. I had some ideas of auto-annealing software applications for engineering and other verticals but those were programmatically deterministic. I wanted something that could “self improve” given a success metric, in this case “total_returns”. I am not a quant so this is an amateur attempt at recreating this for my needs.
So this last weekend I used Antigravity to put this together. I gave it the objective to create a permutation of his library but for trading.
Data Prep
I needed to first create a script for data prep. So that’s what I did. Antigravity assumed I was building an ml model (which you could do if you wanted to) so it separated out the data into a training and validation dataset.
// prepare.py
import os
import yfinance as yf
import pandas as pd
import numpy as np
def prepare_data():
print("Downloading stock data...")
# SPY data from 2000 to present
ticker = "SPY"
df = yf.download(ticker, start="2000-01-01")
if df.empty:
print("Failed to download data.")
return
# Flatten multi-index columns if present (yfinance sometimes does this)
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
# Features are now generated dynamically in trade.py
df.dropna(inplace=True)
print(f"Total rows fetched and processed: {len(df)}")
# Split into Train and Validation
# Train: 2000 - 2018
# Validation: 2019 - Present
train_df = df.loc[:'2018-12-31']
val_df = df.loc['2019-01-01':]
print(f"Training data size: {len(train_df)}")
print(f"Validation data size: {len(val_df)}")
# Create data directory
os.makedirs("data", exist_ok=True)
train_df.to_csv("data/train.csv")
val_df.to_csv("data/val.csv")
print("Data successfully saved to data/train.csv and data/val.csv")
if __name__ == "__main__":
prepare_data()Testing/Evaluation
I then needed a way to create the automation loop to build/test/evaluate.
So I put together a trade script that contained a backtester and the strategy logic. But there was a problem that I ran into later where I couldn’t progress any further due to the limited intelligence of my local models, I needed more variability. So to handle this, a generate_feature method was also added which could essentially generate indicators and other features given the ticker data. These features would be accessible by the trade script.
The initial trade script was a simple Simple Moving Average Cross Over. Note that we are reviewing Total Return, Sharpe Ratio, Max Drawdown, Number of Trades, and Final Cash. Note, we don’t need all of these, I just picked these so my mind can tangibly grasp the performance of the strategy.
// trade.py
import pandas as pd
import numpy as np
import json
class Backtester:
def __init__(self, data_path, initial_capital=10000.0):
self.df = pd.read_csv(data_path, index_col='Date', parse_dates=True)
self.initial_capital = initial_capital
def run(self, strategy_logic, generate_features):
capital = self.initial_capital
position = 0 # 0 means no position, >0 means holding shares
portfolio_values = []
trades = []
# --- NEW LOGIC: Apply features before running the loop ---
self.df = generate_features(self.df.copy())
for index, row in self.df.iterrows():
signal = strategy_logic(row)
if signal == 1 and position == 0:
# Buy
position = capital / row['Close']
capital = 0
trades.append(('BUY', row['Close']))
elif signal == -1 and position > 0:
# Sell
capital = position * row['Close']
position = 0
trades.append(('SELL', row['Close']))
current_value = capital if position == 0 else position * row['Close']
portfolio_values.append(current_value)
# Close out any remaining position at the end
if position > 0:
capital = position * self.df.iloc[-1]['Close']
position = 0
trades.append(('SELL', self.df.iloc[-1]['Close']))
total_return = (capital - self.initial_capital) / self.initial_capital
portfolio_series = pd.Series(portfolio_values)
daily_returns = portfolio_series.pct_change().dropna()
sharpe_ratio = 0.0
if not daily_returns.empty and daily_returns.std() != 0:
sharpe_ratio = (daily_returns.mean() / daily_returns.std()) * np.sqrt(252)
rolling_max = portfolio_series.cummax()
drawdown = portfolio_series / rolling_max - 1.0
max_drawdown = drawdown.min()
return {
"total_return": total_return,
"sharpe_ratio": sharpe_ratio,
"max_drawdown": max_drawdown,
"num_trades": len(trades) // 2,
"final_cash": capital
}
# --- NEW SEPARATED FUNCTIONS ---
def generate_features(df):
"""
Calculates features that the strategy logic previously assumed
existed in the CSV file.
"""
# Moving averages required for the SMA Crossover logic
df['SMA_20'] = df['Close'].rolling(window=20).mean()
df['SMA_50'] = df['Close'].rolling(window=50).mean()
# Optional: you can add other features here as needed
# df['Returns'] = df['Close'].pct_change()
return df
def strategy_logic(row):
"""
Given a row of daily data, return buy/sell signals.
"""
# BASELINE STRATEGY: Simple Moving Average Crossover
if pd.isna(row.get('SMA_20')) or pd.isna(row.get('SMA_50')):
return 0
if row['SMA_20'] > row['SMA_50']:
return 1
elif row['SMA_20'] < row['SMA_50']:
return -1
return 0
# --- MAIN EXECUTION ---
if __name__ == "__main__":
try:
# Pass both strategy_logic and generate_features to the run method
train_tester = Backtester('data/train.csv')
train_metrics = train_tester.run(strategy_logic, generate_features)
val_tester = Backtester('data/val.csv')
val_metrics = val_tester.run(strategy_logic, generate_features)
print(f"train_return: {train_metrics['total_return']:.4f}")
print(f"val_return: {val_metrics['total_return']:.4f}")
print("---")
print(f"train_metrics: {json.dumps(train_metrics)}")
print(f"val_metrics: {json.dumps(val_metrics)}")
except FileNotFoundError:
print("Data files not found. Please run prepare.py first.")Harness for the Loop
Okay, so we now have data, a way to test, and evaluate but we need a way to run it continuously while we do other things. So fundamentally we need to run the trade script, produce the success metrics, and evaluate the results without actually being there. This is where LLMs come in to help! I sent the results along with the entire trade script and past learnings into the model. The model returns the two new functions for the trade_strategy and the generate_features methods. This is returned along with learnings of the past strategy which gets stored in a learnings.md file. Originally I was only keeping the top strategy in memory and improving based on that. After 5 consecutive failures, I would stop as to not waste tokens. I then realized that there could be local minima or maxima so instead top 3 strategies are stored in memory and sent to the model. This gives more context and variability for the next result. Below is the final harness and prompts I used.
Note: For some reason, it appears that this works well with local models for me because I’m cheap and don’t want to spend alot on frontier model tokens. I’m guessing because I’m hitting max token limits. But if you are using local models it needs to be >20B parameter models for consistent instruction following and general data analysis intelligence.
Recommended Local Models: Qwen 3.5 27B, Gemma 4 31B, Devstral Small 24B Instruct
Caution: I added some basic code analysis but you have to be okay with w/e the model writes in the trade script. So ideally run this in a notebook or in a vm or sandbox.
There are parameters you should pay attention to here:
MAX_CONSECUTIVE_FAILS = 5 // Number of times script can fail before stopping
MAX_ITERATIONS = 50 //Max number of iterations
TRAIN_DIR = "train" //Training directory for permutations of trade.py and results
POPULATION_SIZE = 3 //Number of top strategies to consider each evaluation step// harness.py
import os
import re
import json
import subprocess
import shutil
import time
import random
import ast
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
def is_safe_code(code_string):
try:
tree = ast.parse(code_string)
except Exception as e:
print(f"Safety check failed: Could not parse AST ({e}).")
return False
prohibited_functions = {"eval", "exec", "open", "__import__", "globals", "locals", "getattr", "setattr", "delattr"}
prohibited_names = {"os", "sys", "subprocess", "shutil", "builtins"}
prohibited_attrs = {"__class__", "__subclasses__", "__builtins__", "__dict__", "__bases__", "__mro__", "__globals__", "__getattribute__"}
for node in ast.walk(tree):
if isinstance(node, (ast.Import, ast.ImportFrom)):
print("Safety check failed: Imports inside generated code are prohibited.")
return False
if isinstance(node, ast.Call) and isinstance(node.func, ast.Name):
if node.func.id in prohibited_functions:
print(f"Safety check failed: Prohibited function call '{node.func.id}'.")
return False
if isinstance(node, ast.Name):
if node.id in prohibited_names:
print(f"Safety check failed: Prohibited name usage '{node.id}'.")
return False
if isinstance(node, ast.Attribute):
if node.attr in prohibited_attrs:
print(f"Safety check failed: Prohibited attribute '{node.attr}'.")
return False
return True
# Configuration
MAX_CONSECUTIVE_FAILS = 5
MAX_ITERATIONS = 50
TRAIN_DIR = "train"
POPULATION_SIZE = 3
def run_prepare():
print("Running prepare.py...")
subprocess.run(["python", "prepare.py"], check=True)
def run_backtest():
print("Running backtest via trade.py...")
result = subprocess.run(["python", "trade.py"], capture_output=True, text=True, check=True)
out = result.stdout
print(out)
train_ret = None
val_ret = None
for line in out.splitlines():
if line.startswith("train_return:"):
train_ret = float(line.split(":")[1].strip())
elif line.startswith("val_return:"):
val_ret = float(line.split(":")[1].strip())
if train_ret is None or val_ret is None:
raise ValueError("Could not parse backtest results from trade.py output.")
return {"train_return": train_ret, "val_return": val_ret, "raw_output": out}
def read_file(path):
if not os.path.exists(path):
return ""
with open(path, "r", encoding="utf-8") as f:
return f.read()
def write_file(path, content):
with open(path, "w", encoding="utf-8") as f:
f.write(content)
def call_llm(program_instructions, trade_code, learnings, current_results):
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY", "dummy"), # Use dummy if you mock it
base_url=os.getenv("OPENAI_BASE_URL", None)
)
prompt_template = read_file("prompts/prompt_template.md")
prompt = prompt_template.replace("{program_instructions}", program_instructions)\
.replace("{trade_code}", trade_code)\
.replace("{learnings}", learnings)\
.replace("{train_return}", str(current_results['train_return']))\
.replace("{val_return}", str(current_results['val_return']))\
.replace("{raw_output}", current_results.get('raw_output', ''))
print("Querying LLM for improvements...")
response = client.chat.completions.create(
model=os.getenv("OPENAI_MODEL", "gpt-4o"), # Default model
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
# max_tokens=9216
)
return response.choices[0].message.content
def parse_llm_response(response_text):
# Extract python code block
python_blocks = re.findall(r'```python\n(.*?)\n```', response_text, re.DOTALL)
if not python_blocks:
# fallback, maybe starting with ```python\r\n
python_blocks = re.findall(r'```python\r?\n(.*?)\r?\n```', response_text, re.DOTALL)
# Extract markdown code block
markdown_blocks = re.findall(r'```markdown\n(.*?)\n```', response_text, re.DOTALL)
if not markdown_blocks:
markdown_blocks = re.findall(r'```md\r?\n(.*?)\r?\n```', response_text, re.DOTALL)
if not python_blocks:
print("Failed to find python block in LLM response.")
print(response_text)
return None, None
new_trade_code = python_blocks[0]
# If no markdown block is found, maybe it just wrote plain text outside of the python block
# We can try to strip the python block and use the rest as learnings
if markdown_blocks:
new_learnings = markdown_blocks[0]
else:
new_learnings = response_text.replace(f"```python\n{new_trade_code}\n```", "").strip()
return new_trade_code, new_learnings
def main():
if not os.path.exists("data"):
run_prepare()
os.makedirs(TRAIN_DIR, exist_ok=True)
# Resume logic
start_iteration = 0
top_models = [] # List of tuples (val_return, iteration_number)
while os.path.exists(os.path.join(TRAIN_DIR, f"iter_{start_iteration}_trade.py")):
results_file = os.path.join(TRAIN_DIR, f"iter_{start_iteration}_results.json")
if os.path.exists(results_file):
with open(results_file, "r") as f:
try:
res = json.load(f)
vr = res.get("val_return", -float('inf'))
top_models.append((vr, start_iteration))
except json.JSONDecodeError:
pass
start_iteration += 1
top_models.sort(key=lambda x: x[0], reverse=True)
top_models = top_models[:POPULATION_SIZE]
consecutive_fails = 0
if start_iteration > 0:
fails = 0
for it in range(start_iteration - 1, -1, -1):
if any(it == t[1] for t in top_models):
break
fails += 1
consecutive_fails = fails
program_instructions = read_file("prompts/program.md")
for i in range(start_iteration, MAX_ITERATIONS):
print(f"\n--- Iteration {i} ---")
# Run test
try:
results = run_backtest()
except Exception as e:
print(f"Backtest failed: {e}")
break
val_ret = results["val_return"]
# Audit
trade_code = read_file("trade.py")
write_file(os.path.join(TRAIN_DIR, f"iter_{i}_trade.py"), trade_code)
write_file(os.path.join(TRAIN_DIR, f"iter_{i}_results.json"), json.dumps(results))
print(f"Iteration {i} results: Train: {results['train_return']}, Val: {val_ret}")
qualifies = False
if len(top_models) < POPULATION_SIZE:
qualifies = True
elif val_ret > top_models[-1][0]:
qualifies = True
if qualifies:
print(f"New top {POPULATION_SIZE} model! Val Return: {val_ret}")
top_models.append((val_ret, i))
top_models.sort(key=lambda x: x[0], reverse=True)
top_models = top_models[:POPULATION_SIZE]
consecutive_fails = 0
# Save the best explicitly
if top_models[0][1] == i:
print(f"New absolute best model! (Previous: {top_models[1][0] if len(top_models) > 1 else 'None'})")
write_file(os.path.join(TRAIN_DIR, "best_trade.py"), trade_code)
else:
consecutive_fails += 1
print(f"No improvement into Top {POPULATION_SIZE}. Consecutive failures: {consecutive_fails}/{MAX_CONSECUTIVE_FAILS}")
if consecutive_fails >= MAX_CONSECUTIVE_FAILS:
print(f"Reached {MAX_CONSECUTIVE_FAILS} consecutive failures. Stopping optimization loop.")
break
# Get learnings
learnings = read_file(os.path.join(TRAIN_DIR, "learnings.md"))
if learnings.strip() and i > 0:
system_log = f"\n\n[SYSTEM LOG: Actual results for the previous hypothesis: Train Return: {results['train_return']:.4f}, Validation Return: {results['val_return']:.4f}.]\n"
learnings += system_log
write_file(os.path.join(TRAIN_DIR, "learnings.md"), learnings)
# If we failed to improve in previous iterations, revert `trade_code` to a random top model
# so the LLM branches from a successful state instead of a failed state.
if consecutive_fails > 0 and i > 0 and top_models:
sampled_best = random.choice(top_models)
revert_iter = sampled_best[1]
print(f"Reverting to top model iter_{revert_iter}_trade.py for the next hypothesis...")
trade_code = read_file(os.path.join(TRAIN_DIR, f"iter_{revert_iter}_trade.py"))
write_file("trade.py", trade_code)
try:
llm_response = call_llm(program_instructions, trade_code, learnings, results)
except Exception as e:
print(f"LLM Call failed: {e}")
break
new_trade_code, new_learnings = parse_llm_response(llm_response)
if new_trade_code:
if not is_safe_code(new_trade_code):
print("Generated code explicitly failed static security checks. Invalidating iteration.")
break
base_trade = read_file("trade.py")
start_delim = "# --- THESE ARE THE FUNCTIONS THE AGENT SHOULD MODIFY ---"
end_delim = "# -----------------------------------------------------------"
parts = base_trade.split(start_delim)
if len(parts) >= 2:
header = parts[0] + start_delim + "\n\n"
footer_parts = parts[1].split(end_delim)
footer = "\n" + end_delim + (footer_parts[1] if len(footer_parts) > 1 else "")
full_trade_code = header + new_trade_code + footer
else:
full_trade_code = new_trade_code
write_file("trade.py", full_trade_code)
if new_learnings:
current_learnings = read_file(os.path.join(TRAIN_DIR, "learnings.md"))
write_file(os.path.join(TRAIN_DIR, "learnings.md"), current_learnings + "\n\n" + new_learnings.strip() + "\n")
print("Successfully updated trade.py and learnings.md for next iteration.")
else:
print("Failed to update code. Stopping loop.")
break
print("\nOptimization finished.")
if top_models:
print(f"Best validation return found: {top_models[0][0]} at iteration {top_models[0][1]}")
else:
print("No successful iterations.")
if __name__ == "__main__":
main()
Here is the program.md equivalent for the prompt. You might have to tweak this for your specific local model if it isn’t working well and constantly not producing the right code.
This serves as the prompt/instructions that guides the agent on what to do.
# Autoresearch Trading Strategy Optimizer
You are an expert quantitative trader and AI researcher. Your goal is to iteratively develop and optimize a trading strategy that maximizes the **Validation Total Return**.
## The Setup
You have access to a backtesting environment.
- `trade.py` contains the backtesting logic and two key functions: `generate_features(df)` and `strategy_logic(row)`.
- The `generate_features(df)` function allows you to calculate ANY dynamic feature, technical indicator, or mathematical transformation across the entire historical dataframe (e.g. Rolling averages, VWAP, volatilities).
- The `strategy_logic(row)` function takes a single row of pandas data (representing a day in the market containing anything you created in `generate_features`) and must return `1` (Buy), `-1` (Sell), or `0` (Hold/Do nothing).
- The RAW historical data downloaded contains only: `Open`, `High`, `Low`, `Close`, `Adj Close`, and `Volume`.
- Running `python trade.py` will output two metrics:
- `train_return` (Total return over the training period, 2000-2018)
- `val_return` (Total return over the validation period, 2019-Present)
## Your Instructions
1. **Analyze the baseline**: Run `python trade.py` to see the current baseline `train_return` and `val_return`.
2. **Formulate a hypothesis**: Read `train\learnings.md` if it exists and use the learnings to think about how to combine the given features (or invent complex mathematical formulations using them) to predict market movements better than the baseline.
3. **Implement**: Modify ONLY the `generate_features` and `strategy_logic` functions inside `trade.py`. Do not modify the `Backtester` class or the core looping setup.
4. **Evaluate**: Run `python trade.py`. Record the `val_return` AND in `train/learnings.md` record the hypothesis and the results.
5. **Iterate**: If `val_return` improves, keep the change. If it decreases or stays the same, revert the change and try a new hypothesis.
6. **Stopping Condition**: You must track your attempts. If you fail to improve the `val_return` for **5 consecutive iterations**, you have reached the Pareto front. At this point, STOP your optimization loop and present the final `strategy_logic` code and its final `val_return` to the user.
Remember: The ultimate goal is to maximize `val_return`. Be wary of overfitting heavily to `train_return` at the cost of `val_return`.I chose to have a separate learnings.md file that will continuously improve. NOTE this process could be made better so it doesn’t consume more and more tokens via prompt compaction. I won’t provide mine but you should see it appear in your training folder automatically.
Improvements
There are likely many ways to improve this.
- Simplify the program.md
- Autocompaction on learnings.md
- Introduce sliding windows in the backtester to make sure you are not overfitting noise.
- Perhaps abstract the backtester and allow a mode where the backtester can be adjusted by the model with a new program.md to remove biases, overfitting, and improve testability.
- The limitations in program.md are hardcoded, parameterize those or remove them from program.md.
If you can think of ways to improve this or find it useful or useless, let me know in the comments. If you find any alpha and are willing to share, please reach out.
Hope you enjoy experimenting in seeing what results you can get with your local AIs. This “self-improving” workflow can also be applied to many other verticals and even combined with sub-agents to improve and generate new ways of thinking/doing things exponentially. Lets say you have a gene sequencing generation model and validation pipeline. You could throw a generative model in between and use it to intelligently permute the sequence until you have what you are seeking to generate. Just make sure that you can’t mathematically optimize first (which is difficult in the randomly walking ( with the Trump effect ) financial markets).
Leave a Reply